A/B Testing Part I
Posted on April 03 2015 in Statistics
This is going to be my first post on a topic in data science, and in the next few posts including this one, I will talk about A/B testing, specifically how to do it right using Bayesian methods in comparison with the traditional Frequentist hypothesis testing.
the basic concept
As the name implies, A/B testing is a way of testing which one of the two variants, A and B, where A represents the control and B the treatment in a controlled experiment, is statistically significantly better than the other. A and B could be web pages, for example, where in a simplified setting A is the currently deployed web page with a yellow button in the center, and we want to test whether web page B with a blue button in the center is better than A, given that all other elements of the two web pages such as copy text, layouts, background colors, and images are the same.
In search engine marketing, a user types a query health insurance in a search engine say, Google, possibly because he or she wants to enroll in one, and Google shows ads, or so called creatives, at the top and on the side of the search results page. Let's say that an advertiser currently shows a creative like the one below:
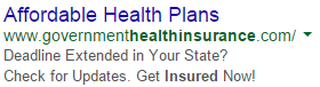
At the time of writing, Obamacare enrollment deadline for 2015 has already passed as it was on February 15th but those few who didn't make the deadline due to special circumstances including, but not limited to, marriage or divorce, technical glitches during the enrollment process, or birth of a new baby were given a week of extension in some states, so it makes sense to have drafted a creative like the one above. Now as the advertiser, can we make this creative better so as to attract more users to click on it? In other words, we want to test whether changing the description lines from the original Deadline Extended in Your State? Check for Updates. Get Insured Now! which we'll label as A to Missed Deadline? You Can Still Get Insured! as B. Of course, we can say there is no measurable difference between these two seemingly similar languages, and it's useless and too time-consuming to test for changes in minor details, such as testing whether adding an exclamation mark at the end of a sentence significantly improves ad clicks, but let's just argue that the former implies a caveat that not all states offer extension and the latter doesn't and testing which creative is more effective is of importance.
How then are we going to measure the effectiveness of the creatives? What does it mean by when one is better than the other? Here the metric of interest is the click-through-rate, or simply CTR, which is basically the number of times an ad is clicked divided by the number of times an ad is shown, clicks over impressions. If there are 5 clicks resulting from a total of 100 impressions for creative A, then A has a CTR of 5/100 or 5%. If A gets a higher CTR than B, then A is defined to be better than B, and vice versa. Now let's set up an A/B test.
Assume creative A that we are currently showing is the control and creative B is the treatment or the test that we compare against A. An A/B test is basically a randomized controlled experiment; that is, let's assume there is a simple random sample of 2000 users who missed the enrollment deadline and are actively searching for their health insurance plans. I show creative A to a randomly chosen 1000 users and creative B to the rest 1000 users. In reality this randomization of showing each user a random creative A or B is done automatically and algorithmically by Google, and we would stop when we reach a total of 2000 users. It would be easier to understand if we think somewhere along the line of first drawing 1000 random numbers without replacement from 1 through 2000 where each number represents a different user and showing A to those 1000 users whose numbers were drawn and otherwise show B. You can then gather the binary data on whether each user in each group clicked 1 or not 0. Also assume in this example that we count only unique clicks. If a user clicks a creative but goes back and clicks again then such action will still be counted as 1. Stop the test when the number of users reaches a total of 2000. Make sure not to stop the test early or continue further testing for the reasons that will be explained in later posts.
After testing, A has received a total of 380 clicks and B 370. In other words, A has a CTR of 0.38 and B 0.37. The primary focus of A/B testing is on which of these two creatives did better in terms of higher CTR and hence should supersede the other. A simple way to do this is to carry out a two-sided proportion test as CTR is a proportion.
the frequentist way
A classical hypothesis testing is the frequentist alternative to the Bayesian method I will write about in later posts. The null hypothesis is that the CTR of A is same as the CTR of B, whereas the alternative hypothesis is the CTR of A is not same as, or different from, the CTR of B. We assume that the null hypothesis is true to begin with and calculate a statistic - a number derived from data - as follows:
where our statistic \(z\) will be normally distributed given that our sample size grows large, by the central limit theorem. We have a sample of 1000 users in each group. Note that \(P_T\) is the observed CTR of the treatment or test group, \(P_T\) the observed CTR of the control group, and \(N_T\) and \(N_C\) refer to the total number of observations in the treatment and control group, respectively.
If our null hypothesis is true, z-statistic will follow the standard normal distribution with mean 0 and standard deviation 1. Let's assume our significance level is 5%. This means that if the value of the z-statistic falls outside the range where 95% of the values from a standard normal distribution fall, we reject the null hypothesis at the 5% significance level. If not, we fail to reject the null. A significance level is basically a false-positive rate, the probability of rejecting the null when the null is true, so setting the significance level to 0.05 means we would erroneously reject the null 5 out of 100 times the experiment is conducted.
the results
In R, the above calculation of z-statistic and comparing it to the point where 95% of the values from a standard normal distribution fall, approximately -1.96 as a lower bound and 1.96 as an upper bound, is done using the function prop.test. Since the p-value is 0.003653 which is less than 0.05, we reject the null that the CTR between A and B are same. The interval (0.01497, 0.1008) contains the true population CTR difference between A and B 95 times out of 100 A/B tests done under the same conditions.
Whew! That's it. Now we say A and B are different in terms of CTR. But so what? To what extent are they different? What is the probability of that extent? That we need to use the Bayesian method to find out. I will discuss the Bayesian alternative which is more intuitive and robust than the frequentist hypothesis testing.