Generating Movie Reviews in Korean with Language Modeling
Posted on March 23 2017 in Natural Language Processing
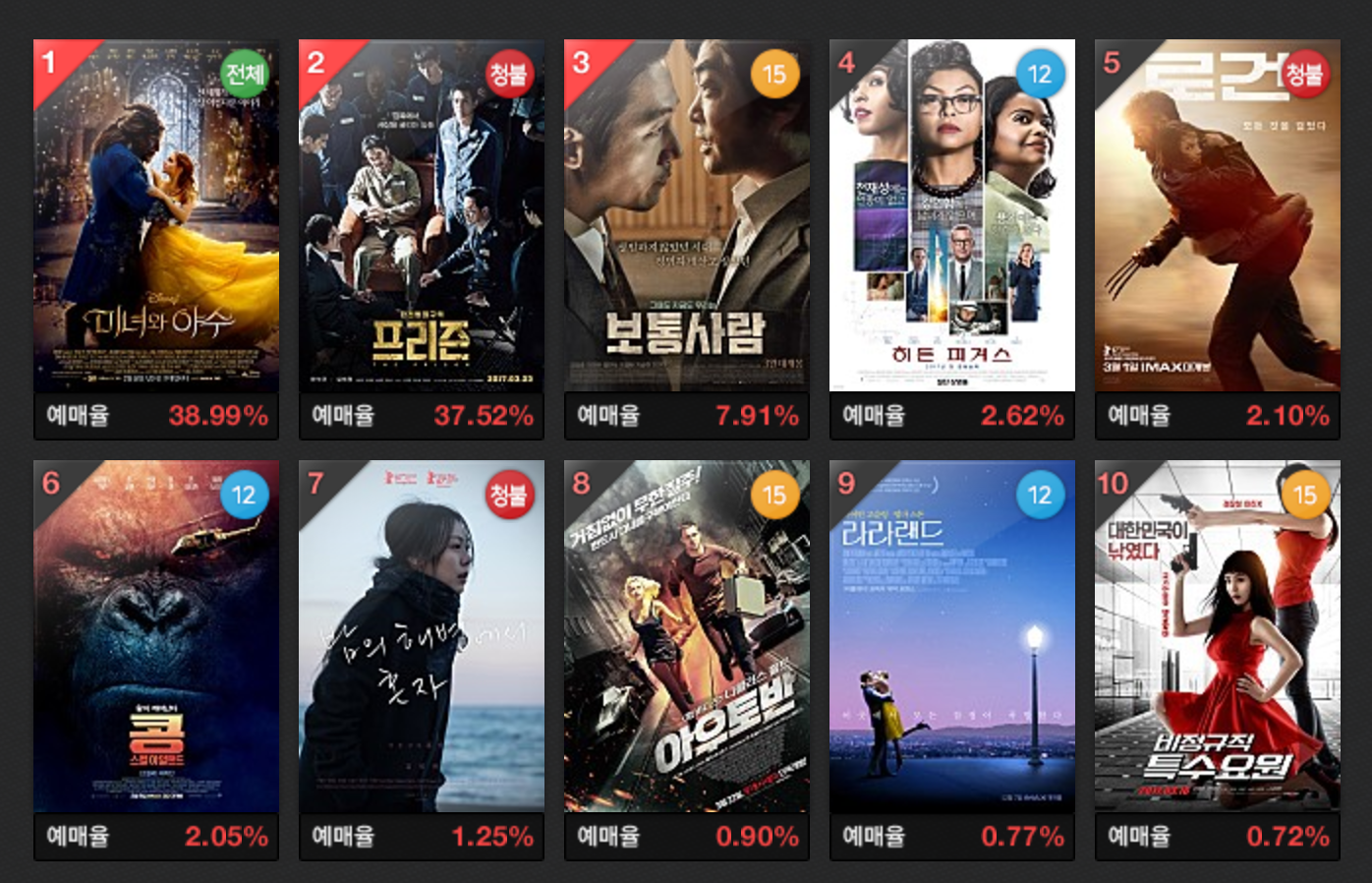
A statistical language modeling is a task of computing the probability of a sentence or sequence of words from a corpus. The standard is a trigram language model where the probability of a next word depends only on the previous two words. But the state-of-the-art as of writing is achieved by using neural networks such as RNN and LSTM and incorporating variants of probabilistic context-free grammars to produce grammatically sound sentences. I'll write about deep learning methods later when I have more free time, so stay tuned. In this post, I write a set of Python scripts to build unigram, bigram, trigram, and linearly interpolated language models using the ratings.txt dataset that contains movie reviews in Korean scraped from Naver Movies (screenshot above) in order to randomly generated movie reviews.
-
tokenize_tag()tokenizes each sentence in a corpus and tags it with an appropriate part-of-speech according to the set of grammatical rules in Korean language with the help ofkonlpymodule. -
calc_ngramcalculates ngrams for each sentence without usingnltkmodule. -
calc_probabilities()calculates unigram, bigram, and trigram probabilities given a training corpus, which is a list of sentences where each sentence is a string with tokens separates by spaces, ending in a newline character. This function outputs three python dictionaries where the keys are tuples expressing the ngram and the value is the log probability of that ngram. -
q1_output()writes unigram, bigram, trigrams, and their respective log probabilities to a text file. -
score()assigns a probability to each training sentence based on ngrams and their probabilities. -
score_output()writes sentence probabilities to a text file. -
linearscore()assigns a probability to each training sentence based on a linear interpolation among ngrams with \(\lambda\) fixed to \(1/3\), but the optimal value of \(\lambda\) can be found using a cross-validation.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import math
import time
from collections import defaultdict
from konlpy.tag import Twitter
START_SYMBOL = '*'
STOP_SYMBOL = 'STOP'
MINUS_INFINITY_SENTENCE_LOG_PROB = -1000
def read_data(filename):
with open(filename, 'r') as f:
corpus = [row.split('\t') for row in f.read().splitlines()]
corpus = corpus[1:]
return corpus
def tokenize_tag(corpus):
pos_tagger = Twitter()
return ['/'.join(a) for a in pos_tagger.pos(corpus)]
def calc_ngram(sentence, n):
tokens = [START_SYMBOL] * (n-1) + sentence.strip().split() + [STOP_SYMBOL]
ngrams = [tuple(tokens[i:(i+n)]) for i in range(len(tokens)-n+1)]
return ngrams
def calc_probabilities(training_corpus):
unigram_c = defaultdict(int)
bigram_c = defaultdict(int)
trigram_c = defaultdict(int)
for sent in training_corpus:
tokens_u = calc_ngram(sent, 1)
tokens_b = calc_ngram(sent, 2)
tokens_t = calc_ngram(sent, 3)
for unigram in tokens_u:
unigram_c[unigram] += 1
for bigram in tokens_b:
bigram_c[bigram] += 1
for trigram in tokens_t:
trigram_c[trigram] += 1
unigram_total = sum(unigram_c.values())
unigram_p = {a: math.log(unigram_c[a], 2) - math.log(unigram_total, 2) for a in unigram_c}
unigram_c[START_SYMBOL] = len(training_corpus)
bigram_p = {(a, b): math.log(bigram_c[(a, b)], 2) - math.log(unigram_c[(a,)], 2) for a, b in bigram_c}
bigram_c[(START_SYMBOL, START_SYMBOL)] = len(training_corpus)
trigram_p = {(a, b, c): math.log(trigram_c[(a, b, c)], 2) - math.log(bigram_c[(a, b)], 2) for a, b, c in trigram_c}
return unigram_p, bigram_p, trigram_p
def q1_output(unigrams, bigrams, trigrams, filename):
outfile = open(filename, 'w')
unigrams_keys = list(unigrams.keys())
unigrams_keys.sort()
for unigram in unigrams_keys:
outfile.write('UNIGRAM ' + unigram[0] + ' ' + str(unigrams[unigram]) + '\n')
bigrams_keys = list(bigrams.keys())
bigrams_keys.sort()
for bigram in bigrams_keys:
outfile.write('BIGRAM ' + bigram[0] + ' ' + bigram[1] + ' ' + str(bigrams[bigram]) + '\n')
trigrams_keys = list(trigrams.keys())
trigrams_keys.sort()
for trigram in trigrams_keys:
outfile.write('TRIGRAM ' + trigram[0] + ' ' + trigram[1] + ' ' + trigram[2] + ' ' + str(trigrams[trigram]) + '\n')
outfile.close()
def score(ngram_p, n, corpus):
scores = []
for sent in corpus:
ngrams = calc_ngram(sent, n)
prob_sent = 0
if all(ngram in ngram_p for ngram in ngrams):
for ngram in ngrams:
prob_sent += ngram_p[ngram]
scores.append(prob_sent)
else:
scores.append(MINUS_INFINITY_SENTENCE_LOG_PROB)
return scores
def score_output(scores, filename):
outfile = open(filename, 'w')
for score in scores:
outfile.write(str(score) + '\n')
outfile.close()
def linearscore(unigrams, bigrams, trigrams, corpus):
scores = []
global_lambda = 1.0 / 3
for sent in corpus:
ngrams = calc_ngram(sent, 3)
lin_interpolated_score = 0
for trigram in ngrams:
p3 = trigrams.get(trigram, MINUS_INFINITY_SENTENCE_LOG_PROB)
p2 = bigrams.get(trigram[1:3], MINUS_INFINITY_SENTENCE_LOG_PROB)
p1 = unigrams.get(trigram[2], MINUS_INFINITY_SENTENCE_LOG_PROB)
lin_interpolated_score += math.log(global_lambda * (2**p3 + 2**p2 + 2**p1), 2)
scores.append(lin_interpolated_score)
return scores
DATA_PATH = 'PATH_TO_YOUR_DATA_FILES'
OUTPUT_PATH = 'PATH_TO_YOUR_OUTPUT'
def main():
time.clock()
infile = DATA_PATH + 'ratings.txt'
train = read_data(infile)
doc = [tokenize_tag(row[1]) for row in train]
corpus = []
for tag_token in doc:
sent = ' '.join([elem.split('/')[0] for elem in tag_token])
corpus.append(sent)
outfile = open(OUTPUT_PATH + 'corpus.txt', 'w')
for row in corpus:
outfile.write(row + '\n')
outfile.close()
unigrams, bigrams, trigrams = calc_probabilities(corpus)
q1_output(unigrams, bigrams, trigrams, OUTPUT_PATH + 'ngram_probs.txt')
uniscores = score(unigrams, 1, corpus)
biscores = score(bigrams, 2, corpus)
triscores = score(trigrams, 3, corpus)
score_output(uniscores, OUTPUT_PATH + 'unigram_scores.txt')
score_output(biscores, OUTPUT_PATH + 'bigram_scores.txt')
score_output(triscores, OUTPUT_PATH + 'trigram_scores.txt')
linearscores = linearscore(unigrams, bigrams, trigrams, corpus)
score_output(linearscores, OUTPUT_PATH + 'linear_scores.txt')
print('Time: ' + str(time.clock()) + ' sec')
if __name__=='__main__':
main()
Once we have unigram_scores.txt, bigram_scores.txt, trigram_scores.txt, and linear_scores.txt files, we can compute their perplexities on ratings.txt using the Python script below. The resulting perplexities of different language models are shown:
- Unigram LM: \(1279.036\)
- Bigram LM: \(52.768\)
- Trigram LM: \(10.357\)
- Linear Interpolation: \(15.068\)
As we can see, the trigram language model does the best on the training set since it has the lowest perplexity. The linear interpolation model actually does worse than the trigram model because we are calculating the perplexity on the entire training set where trigrams are always seen. If we were to calculate the perplexity on the test set where new trigrams exist, then we'd expect to see lower score on the linear interpolation than on the trigram model.
# an example usage
python3 perplexity.py trigram_scores.txt corpus.txt
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import sys
def main():
if len(sys.argv) < 2:
print('Usage: python perplexity.py <file of scores> <file of sentences that were scored>')
exit(1)
infile = open(sys.argv[1], 'r')
scores = infile.readlines()
infile.close()
infile = open(sys.argv[2], 'r')
sentences = infile.readlines()
infile.close()
M = 0
for sentence in sentences:
words = sentence.split()
M += len(words) + 1
perplexity = 0
for score in scores:
perplexity += float(score.split()[0]) # assume log probability
perplexity /= M
perplexity = 2 ** (-1 * perplexity)
print('The perplexity is', perplexity)
if __name__=='__main__':
main()
Now, I'm going to randomly generate sentences based on the trigram language model. The following Python script outputs 20 randomly generated movie reviews.
-
partial_match()outputs all key-value pairs in the trigram model dictionary that have the same first two elements of an input key. -
weighted_pick()picks the next word in a sequence of words from a conditional probability distribution. -
generate_sentence()randomly creates a sentence.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import numpy as np
from collections import defaultdict
START_SYMBOL = '*'
STOP_SYMBOL = 'STOP'
def partial_match(key, ngram_dict):
for k, v in ngram_dict.items():
if all(k1 == k2 or k2 is None for k1, k2 in zip(k, key)):
yield k, v
def weighted_pick(words, ngram_dict, n):
partial_dict = dict(partial_match(words, ngram_dict))
next_words = []
probs = []
items = partial_dict.items()
for trigram, log_prob in items:
next_words.append(trigram[-1])
probs.append(2 ** float(log_prob))
norm_probs = [a / sum(probs) for a in probs]
key = np.random.choice(next_words, 1, p=norm_probs)
return str(key[0])
def generate_sentence(ngram_dict, n):
sentence = []
words = [START_SYMBOL] * (n-1) + [None]
word = weighted_pick(words, ngram_dict, n)
while word != STOP_SYMBOL:
if n != 1:
del words[0]
del words[-1]
words.append(word)
words.append(None)
sentence.append(word)
word = weighted_pick(words, ngram_dict, n)
print(' '.join(sentence))
OUTPUT_PATH = 'PATH_TO_YOUR_OUTPUT'
def main():
with open(OUTPUT_PATH + 'ngram_probs.txt', 'r') as f:
ngrams = [row.split(' ') for row in f.read().splitlines()]
trigram_list = [row[1:] for row in ngrams if row[0] == 'TRIGRAM']
trigram_dict = defaultdict()
for a1, a2, a3, b in trigram_list:
trigram_dict[(a1, a2, a3)] = float(b)
print('Generating random sentences...')
for i in range(20):
generate_sentence(trigram_dict, 3)
if __name__=='__main__':
main()
Few interesting sentences that got generated:
- 진짜 엄청 신선하고 몰입도 있고 재밌었 어요 ~
- 이민정 정말 이쁘 고 스토리 전개도 억지 스럽 다고 생각하는 데 이번 역 은 안 봐 지 하고 개속 봣 는 데 .. 5 ~ 7 점 이 아깝 다
- 여친 따라 봤 다 후회 없 음
- ㄷㄷㄷ 담배 만 피우다 끝나는 영화 . 다 들 연기 안습 ㅡㅡ 스토리 가 주 운송 수단 이라는 점 에서 그 이상 의 디테 일도 쉣 ... 디테 일도 좋 았 어요 . 이 드라마 한가지 만 집중 적 으로 성동일 팬 이라 봤 지만 역시 재미있네 요
- 잔잔 하니 감동 도 없는 영화
- 영화 끝나고 스트레스 받았 다 는 것 ...
- 어쩔 수 없이 1 점 이다 .
Other sentences that seemed grammatically incorrect or sarcastic:
- 미국 판 두 개 는 과거 들 과거 속 으로 들어가서 머리카락 이 영수증 분쇄기 에 찡 함
- 이 것 이 아 무 생각 없이 볼 만 했 던 신의 ... 지금 도 가슴 설레는 영화 ost 앨범 도 구매 해서 봤 다 .
- 한 남자 를 돌려 애써 모면 하려 하 는데 내 가 느와르 를 원한 다 진짜 !!!"""" 처음 엔 재밌게 만 봤 는데도 눈시울 붉 혔 네 요 ... 어디 유쾌 한 공정 드라마 . 로튼 토마토 가 모든 것 들 은 멋진 훈남 훈녀 다 .
- 1 점 드립니 다 . 최고 !
- 잔잔 한 감동 을 주는 공포영화 는 절대 영화관 가서 봣다 가 S 급
- 현재 tv 시트콤 수준 이 1998 년 당시 에는 파격 적 인 제목 은 기술자 들 이야 말로 다른 배트맨 시리즈 를 다시 찍어 봐 . 38 분 까지 역겨운 짓 하던 니 들 이 이 것 보단 재밌겠 다 능
Most short sentences that were generated seemed okay and few were actually directly taken from the training set which is expected, while long sentences or sentences with movie names in them sounded awkward and unnatural.