Hadoop and MapReduce Woes
Posted on October 09 2015 in Big Data
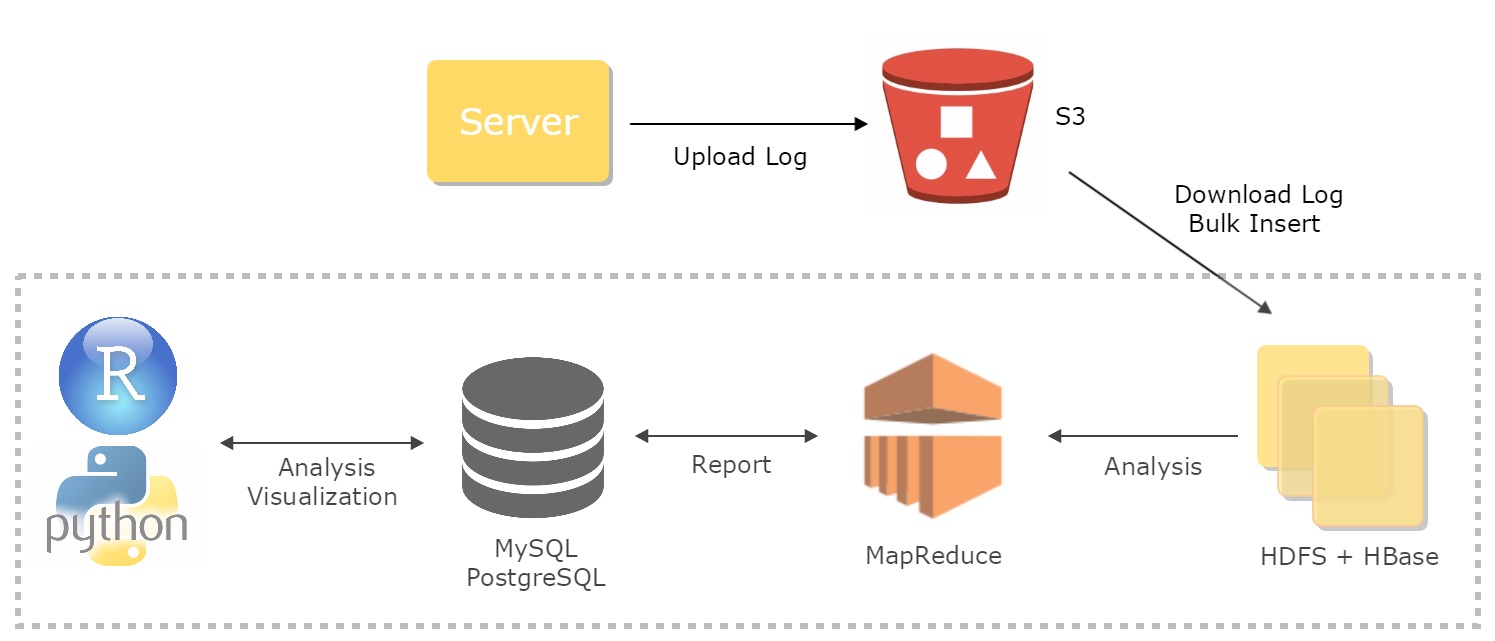
As a data scientist, not only do I analyze data and present the findings, but I also make careful engineering choices that allow collecting, storing, and analyzing data to be more robust and efficient. The traditional data system architecture works like the following:
- Collect and upload server logs to Amazon S3.
- Download logs and bulk insert them into HDFS and HBase.
- Use MapReduce to clean and wrangle log data as well as analyze them.
- Store the intermediary output in a MySQL or PostgreSQL table.
- Use R and/or Python to create dashboards and visualizations and further analyze data.
This structural flow works pretty well, but in the end it proves to be inconvenient. The PC hardwares that are the computing clusters break down too often. Since we can't continue to buy more hardwares to increase memory and computation power, the daily batch jobs run slow over time with the increase in the size of log data. Moreover, writing and running MapReduce code takes quite a bit of time and practice for an average analyst.
One solution to tackle these problems is using Apache Spark. The new data system architecture looks like this:
- Collect and store logs and intermediary outputs in Amazon S3.
- Clean, wrangle, and analyze log data using Spark clusters in Amazon EC2 and run batch jobs there as well.
- Use R and/or Python to do additional analysis and create visualizations as necessary.
This is so much simpler than using Hadoop and MapReduce! Remember that Spark servers require good amount of memory so it's advisable to use EC2 R3 instance. All the servers run in the AWS cloud. By doing this, there's no need to copy and parse log data every morning which take more than 10 hours, while Spark, S3, and EC2 combo handles the same process in less than an hour! Awesome!