Hadoop and MapReduce Woes
Posted on October 09 2015 in Big Data • Tagged with hadoop, mapreduce, mrjob, spark • Leave a comment
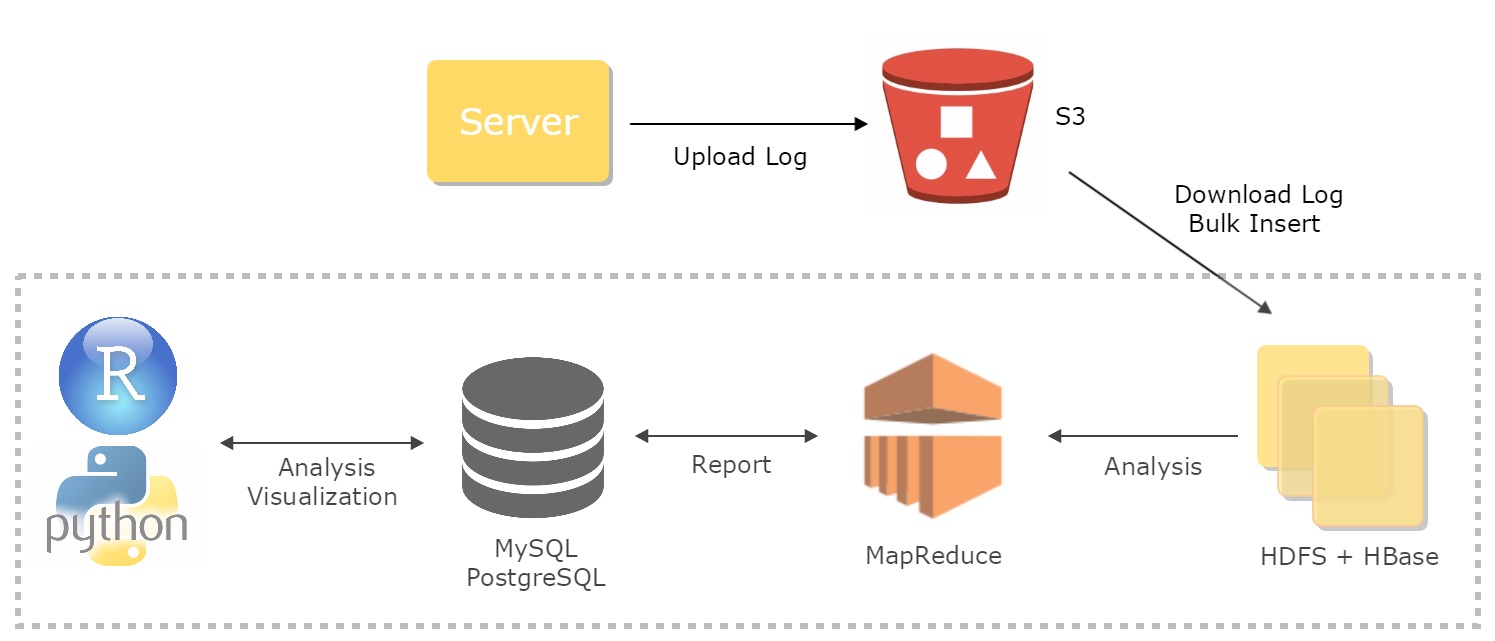
As a data scientist, not only do I analyze data and present the findings, but I also make careful engineering choices that allow collecting, storing, and analyzing data to be more robust and efficient. The traditional data system architecture works like the following:
- Collect and upload server logs to Amazon …